
TL;DR; Google is the most influential company on Github, but judging by the number of employees, Facebook fares better. As expected, javascript is the most used language.
To calculate the most influential companies we calculate the number of repositories multiplied by the number of stars received.
Show the code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
#get the data
import requests
import csv
data = []
head = {'Authorization': 'token code'}
def saveData(body, company):
for item in body["items"]:
data.append([company, item["full_name"], item["stargazers_count"], item["watchers_count"], item["language"]])
def getNextUrl(headers):
links = headers.get('link', None)
if links is not None:
individualLinks = links.split(",")
firstLink = individualLinks[0].split(";")
if "next" in firstLink[1]:
nextPageUrl = firstLink[0][1:-1]
return nextPageUrl
else:
return None
return None
def getData(url):
response = requests.get(url, headers=head)
return response
def queryApi(url, company):
content = getData(url)
saveData(content.json(), company)
nextUrl = getNextUrl(content.headers)
if nextUrl:
return queryApi(nextUrl, company)
else:
return None
company_lists = {
"google" : ["google", "googlesamples"],
"facebook" : ["facebook"],
"apache" : ["apache"],
"microsoft" : ["microsoft"],
"mozilla" : ["mozilla"],
"apple": ["apple"],
"amazon": ["amzn", "amazonwebservices", "aws"]
}
for key, value in company_lists.items():
for company in value:
queryApi("https://api.github.com/search/repositories?q=org:{}&type=Repositories&per_page=100".format(company), key)
with open('../data/github-companies/companies2.csv', 'w') as myfile:
wr = csv.writer(myfile)
wr.writerow(['Company', 'Repository', 'Stars', 'Watchers', 'Language'])
for x in data:
wr.writerow(x)
Google is the most influential company on Github, followed up by Facebook, Microsoft, Apache and Mozilla. Although not in the top, we included Amazon and Apple to see how the other two big tech companies are doing:
Show the code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#calculate most influential
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import datetime
%matplotlib inline
data = pd.read_csv(
"data/github-companies/companies.csv"
)
stars = data[["Company", "Stars"]].copy()
stars_count = stars.groupby(["Company"]).sum().sort_values("Stars", ascending=False)
def make_autopct(values):
def my_autopct(pct):
total = sum(values)
val = int(round(pct*total/100.0))
return '{p:.2f}% ({v:,})'.format(p=pct,v=val)
return my_autopct
explode = (0.07, 0, 0, 0, 0, 0, 0)
stars_count.plot(kind="pie", y="Stars", autopct=make_autopct(stars_count["Stars"]),
explode=explode, shadow=True, startangle=140, figsize=(12,12), title="Total number of stars per company with percentage")
plt.ylabel('')
plt.savefig('data/github-companies/stars.png')
| Company | Stars |
|---|---|
| 690623 | |
| 552130 | |
| microsoft | 296351 |
| apache | 199440 |
| mozilla | 122640 |
| apple | 72066 |
| amazon | 44504 |
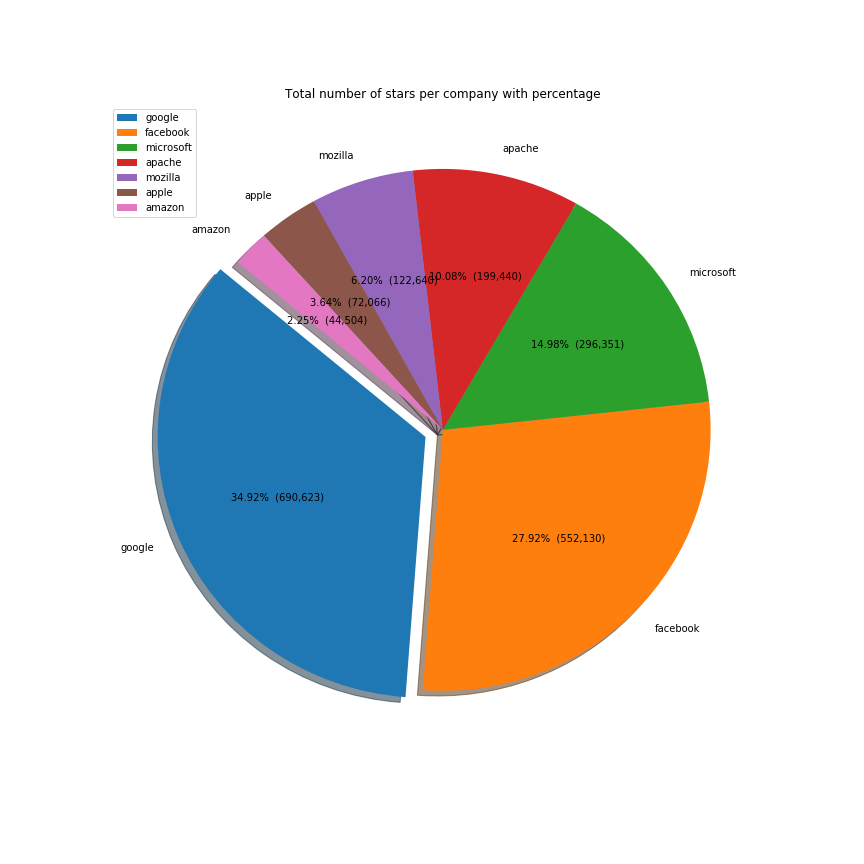
But Google is much bigger than Facebook. So it would be fairer to judge the company by the number of employees. Github stars per capita is in Facebook's favour, suggesting that the company gives more to open source given its size:
Show the code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
employees = {
"google": 72053,
"facebook" : 20658,
"microsoft" : 124000,
"mozilla" : 1050
}
stars_with_employees = stars_count.iloc[pd.np.r_[0:3, 4:5]].reset_index()
stars_with_employees["Employees"] = stars_with_employees["Company"].map(employees)
stars_with_employees["stars_per_employee"] = stars_with_employees.apply(lambda x: round(x.Stars / x.Employees,1), axis = 1)
stars_with_employees.sort_values("stars_per_employee", ascending=False)
explode = (0, 0.1, 0, 0)
stars_with_employees[["stars_per_employee", "Company"]].set_index("Company").plot(kind="pie", y="stars_per_employee", autopct=make_autopct(stars_with_employees["stars_per_employee"]),
explode=explode, shadow=True, startangle=140, figsize=(12,12), title="Github stars per employee - percentage and total value")
plt.ylabel('')
plt.savefig('data/github-companies/stars_per_employee.png')
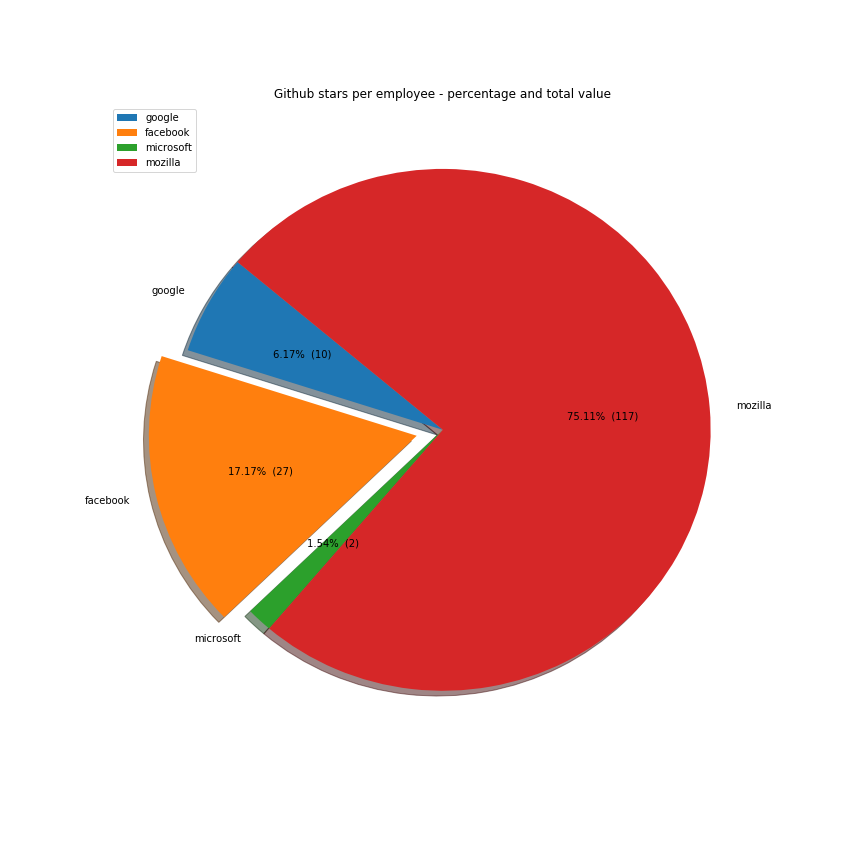
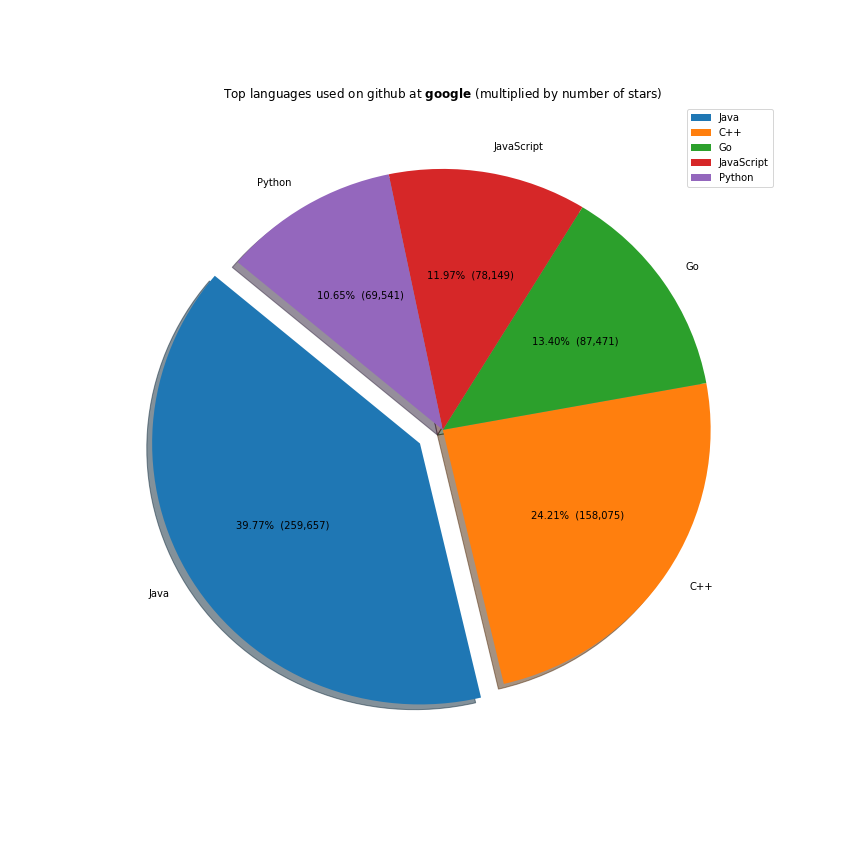
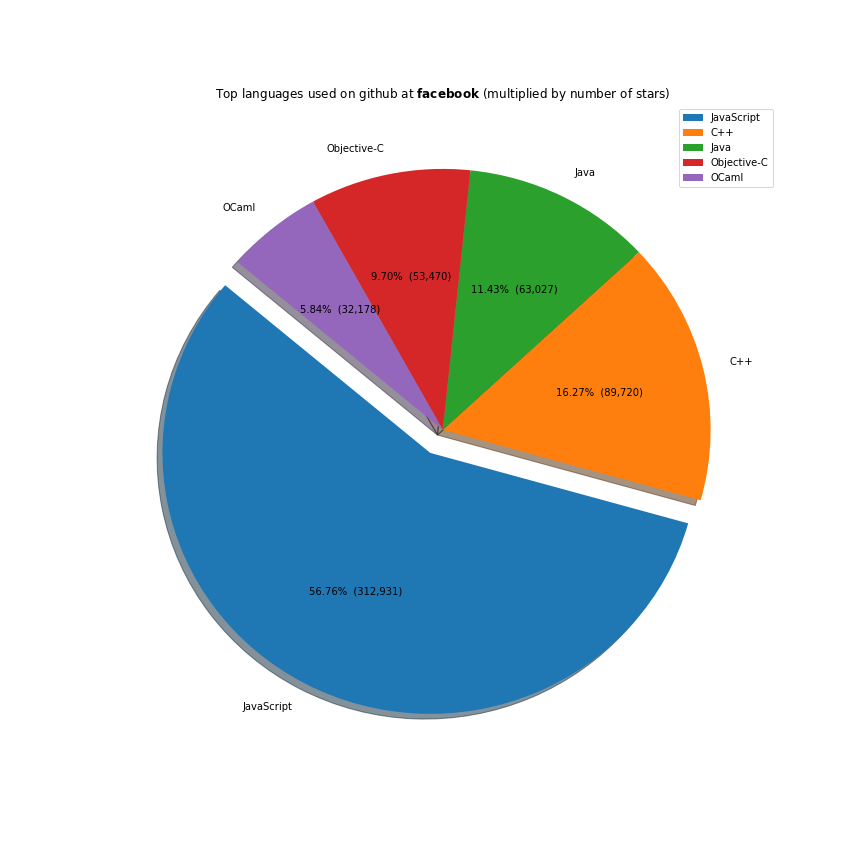
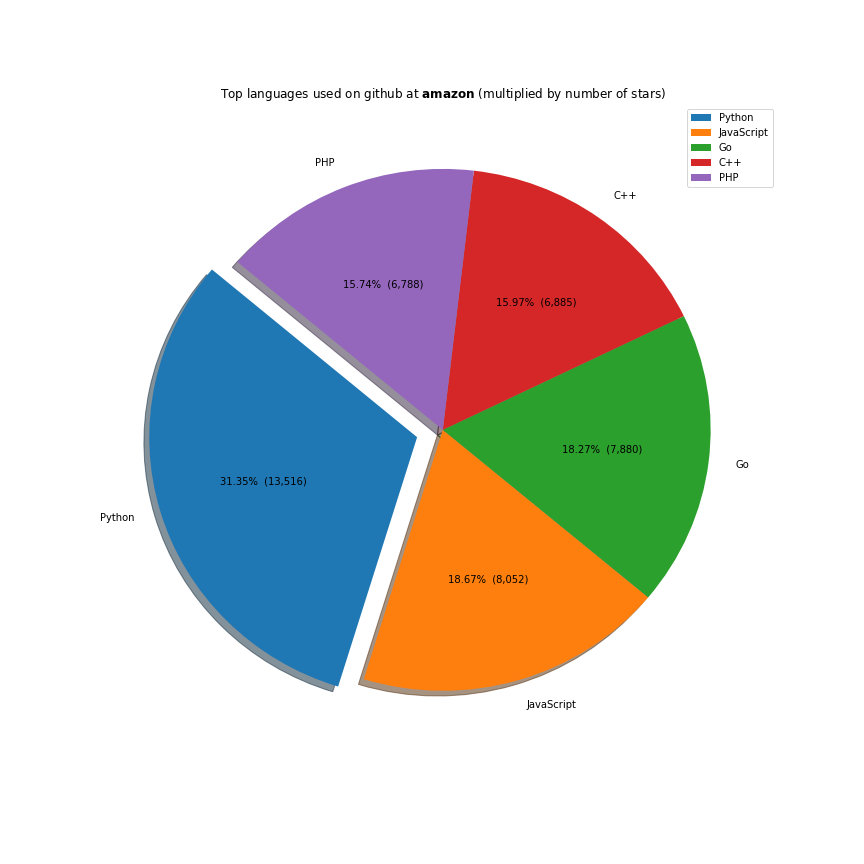
The majority of the work these companies do is done on the javascript ecosystem. Java, C++ and Python are also receiving a lot of support. Facebook is investing a lot in Ocaml, Apache in Scala and Microsoft in Typescript.
Show the code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
language = data[["Company", "Language", "Stars"]].copy()
def filter_by_company(df, company):
return df[df["Company"] == company].copy()
def group_by_language_stars(df):
return df.groupby(["Language"]).sum().sort_values("Stars", ascending=False)
def languages_pie(df, company):
explode = (0.1, 0, 0, 0, 0)
df[~df.index.isin(["HTML", "CSS"])].iloc[:5].plot(kind="pie", y="Stars", autopct=make_autopct(df["Stars"]),
explode=explode, shadow=True, startangle=140, figsize=(12,12), title="Top languages used on github at $\\bf{}$ (multiplied by number of stars)".format(company))
plt.ylabel('')
plt.savefig('data/github-companies/languages_at_{}.png'.format(company))
company_lists = ["google", "facebook", "apache", "microsoft", "mozilla", "apple", "amazon"]
for company in company_lists:
(language.pipe(filter_by_company, company=company)
.pipe(group_by_language_stars)
.pipe(languages_pie, company)
)
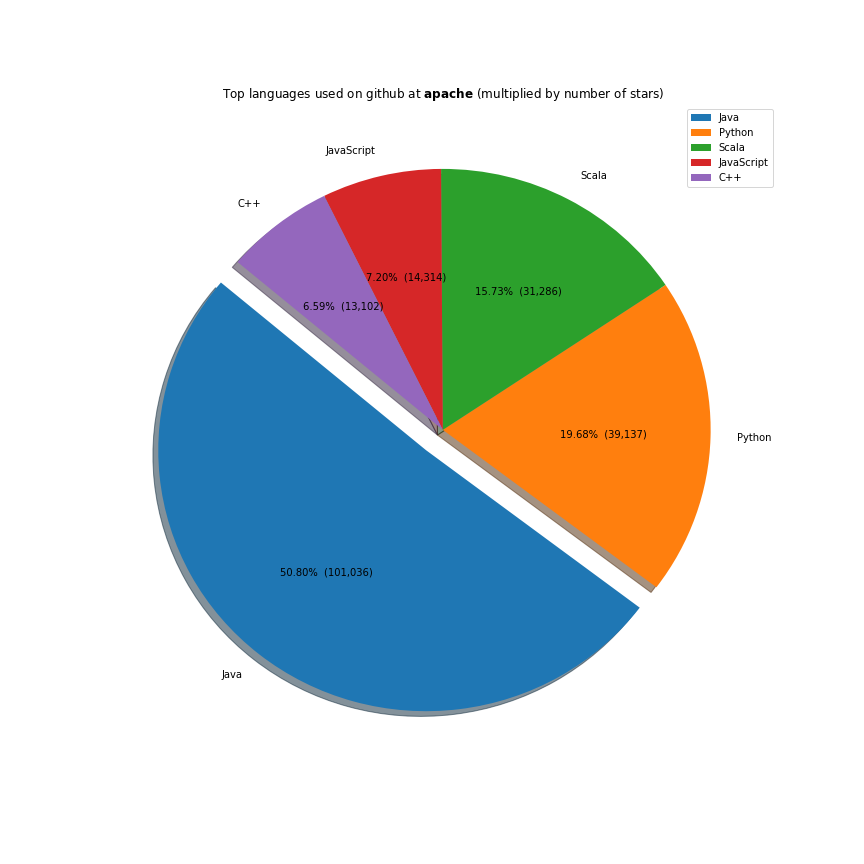
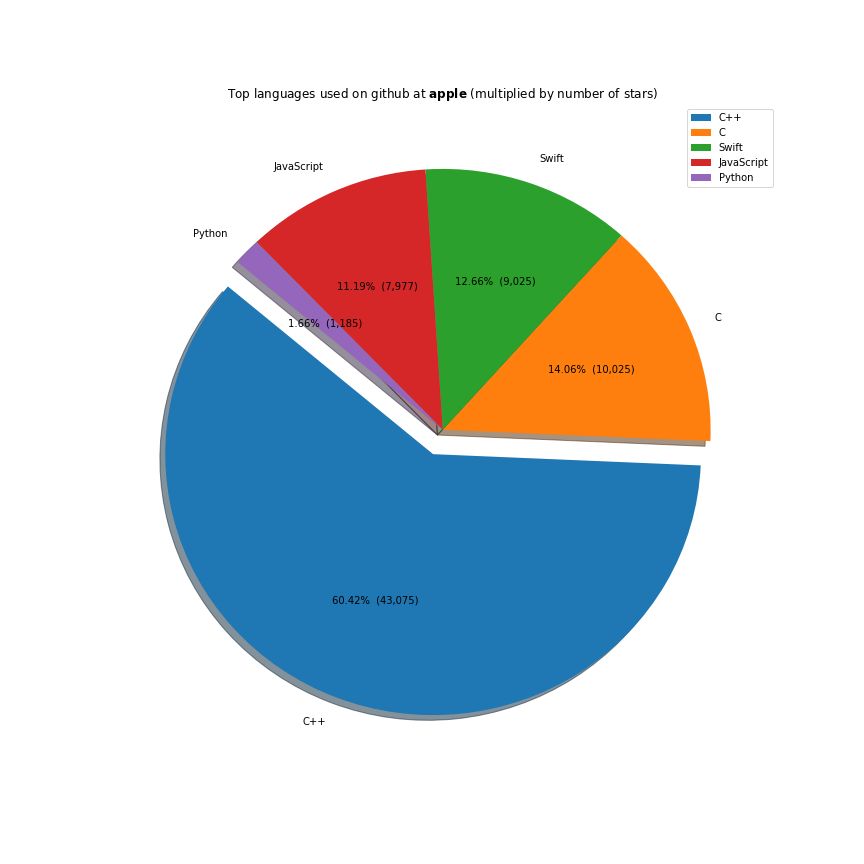
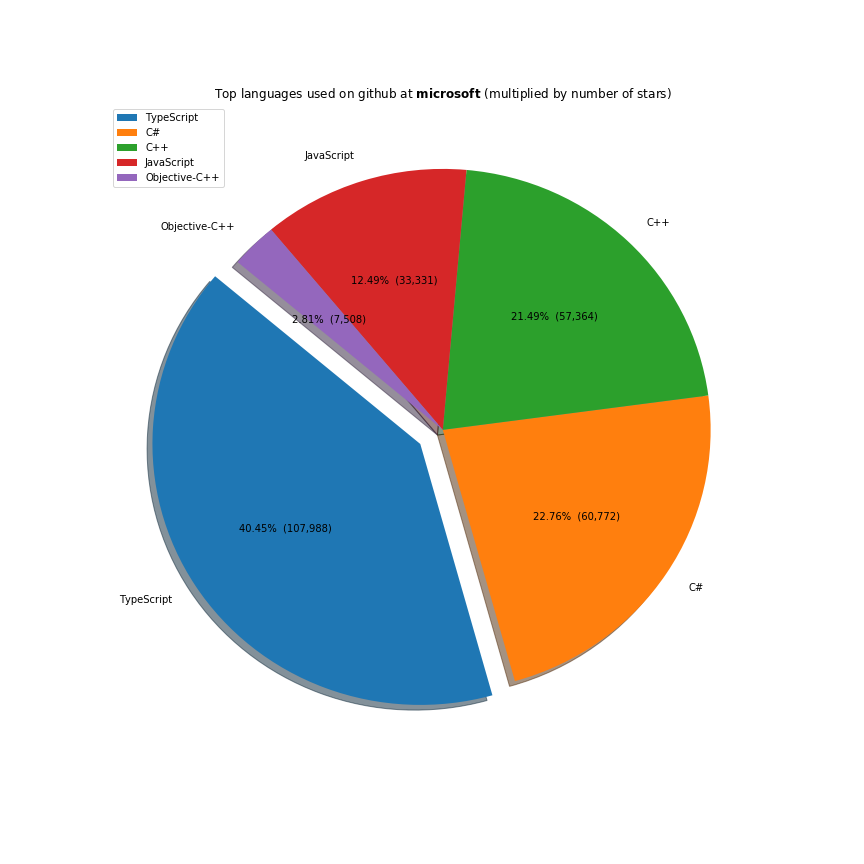
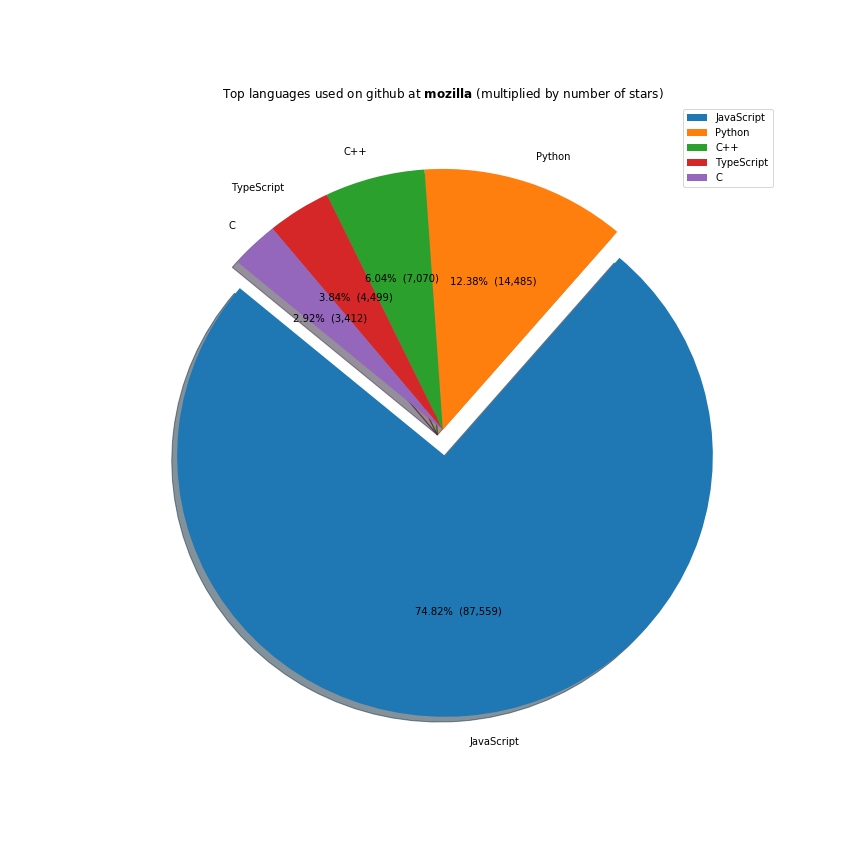
Full code here.