# load the data
X_train=pd.read_csv("data/russian_house_market/train.csv",parse_dates=['timestamp'])X_test=pd.read_csv("data/russian_house_market/test.csv")
1
X_train.describe()
id
full_sq
life_sq
floor
max_floor
material
build_year
num_room
kitch_sq
state
...
cafe_count_5000_price_2500
cafe_count_5000_price_4000
cafe_count_5000_price_high
big_church_count_5000
church_count_5000
mosque_count_5000
leisure_count_5000
sport_count_5000
market_count_5000
price_doc
count
30471.000000
30471.000000
24088.000000
30304.000000
20899.000000
20899.000000
1.686600e+04
20899.000000
20899.000000
16912.000000
...
30471.000000
30471.000000
30471.000000
30471.000000
30471.000000
30471.000000
30471.000000
30471.000000
30471.000000
3.047100e+04
mean
15237.917397
54.214269
34.403271
7.670803
12.558974
1.827121
3.068057e+03
1.909804
6.399301
2.107025
...
32.058318
10.783860
1.771783
15.045552
30.251518
0.442421
8.648814
52.796593
5.987070
7.123035e+06
std
8796.501536
38.031487
52.285733
5.319989
6.756550
1.481154
1.543878e+05
0.851805
28.265979
0.880148
...
73.465611
28.385679
5.418807
29.118668
47.347938
0.609269
20.580741
46.292660
4.889219
4.780111e+06
min
1.000000
0.000000
0.000000
0.000000
0.000000
1.000000
0.000000e+00
0.000000
0.000000
1.000000
...
0.000000
0.000000
0.000000
0.000000
0.000000
0.000000
0.000000
0.000000
0.000000
1.000000e+05
25%
7620.500000
38.000000
20.000000
3.000000
9.000000
1.000000
1.967000e+03
1.000000
1.000000
1.000000
...
2.000000
1.000000
0.000000
2.000000
9.000000
0.000000
0.000000
11.000000
1.000000
4.740002e+06
50%
15238.000000
49.000000
30.000000
6.500000
12.000000
1.000000
1.979000e+03
2.000000
6.000000
2.000000
...
8.000000
2.000000
0.000000
7.000000
16.000000
0.000000
2.000000
48.000000
5.000000
6.274411e+06
75%
22855.500000
63.000000
43.000000
11.000000
17.000000
2.000000
2.005000e+03
2.000000
9.000000
3.000000
...
21.000000
5.000000
1.000000
12.000000
28.000000
1.000000
7.000000
76.000000
10.000000
8.300000e+06
max
30473.000000
5326.000000
7478.000000
77.000000
117.000000
6.000000
2.005201e+07
19.000000
2014.000000
33.000000
...
377.000000
147.000000
30.000000
151.000000
250.000000
2.000000
106.000000
218.000000
21.000000
1.111111e+08
8 rows × 276 columns
1
2
3
4
# correlation with target feature
corr_matrix=X_train.corr()corr_matrix["price_doc"].sort_values(ascending=False)
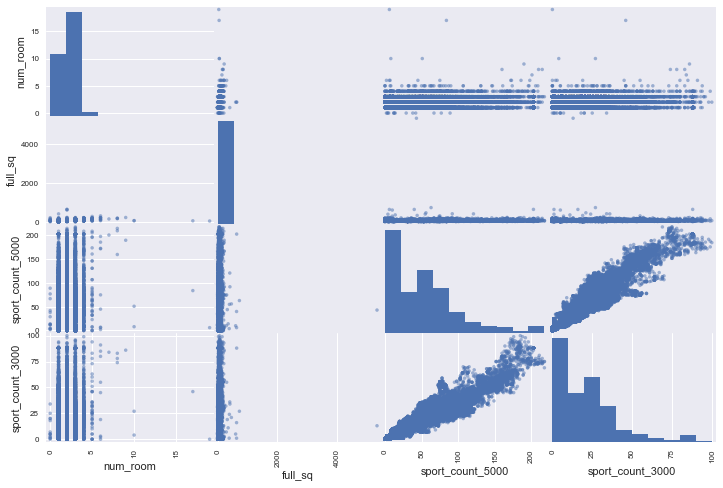
# correlations between most important features
attributes=["num_room","full_sq","sport_count_5000","sport_count_3000"]pd.plotting.scatter_matrix(X_train[attributes],figsize=(12,8))
1
2
3
4
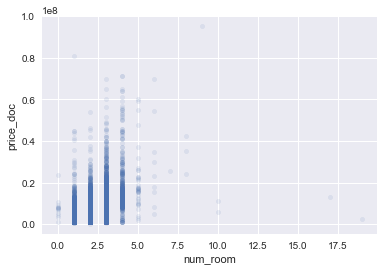
# most interesting is the num_room, so let's plot it against the target feature
# as we can see
X_train.plot(kind="scatter",x="num_room",y="price_doc",alpha=0.1)
1
2
3
4
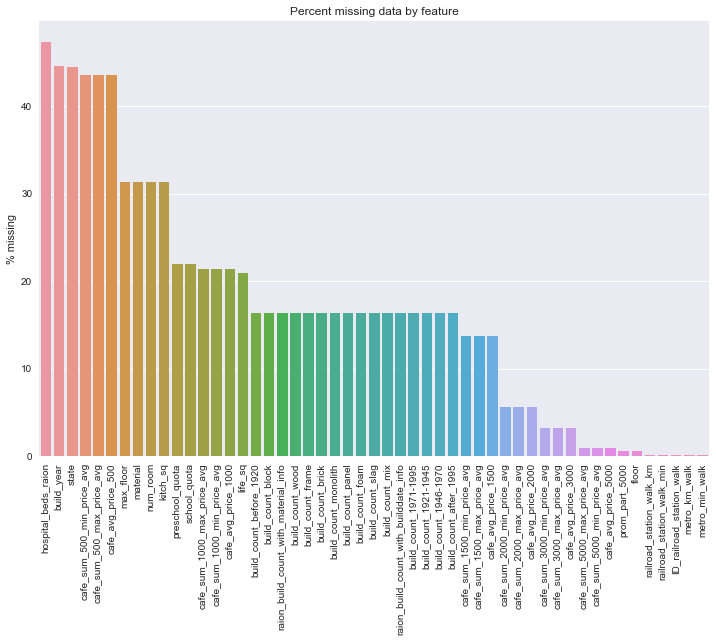
# missing data
train_na=(X_train.isnull().sum()/len(X_train))*100# see the percentage
train_na=train_na.drop(train_na[train_na==0].index).sort_values(ascending=False)# drop the ones that are zeros
1
2
3
4
5
6
# plot the missing data
f,ax=plt.subplots(figsize=(12,8))plt.xticks(rotation='90')sns.barplot(x=train_na.index,y=train_na)ax.set(title='Percent missing data by feature',ylabel='% missing')
1
2
3
4
5
6
7
8
# fill the na and get dummy variables from categorical data
X_all=pd.concat(objs=[X_train,X_test],axis=0)assertisinstance(X_all,pd.DataFrame)X_all["timestamp"]=X_all["timestamp"].apply(lambdarow:str(row).split("-")[0])X_all.fillna(X_all.mean(),inplace=True)X_all=pd.get_dummies(X_all)
# split the data
X_train=pd.DataFrame(X_all[:len(X_train)])X_test=pd.DataFrame(X_all[len(X_train):])length=len(X_train)y=X_train["price_doc"]X_train_transformed=X_train.drop(["price_doc"],axis=1).copy()
# test it with linear regression
fromsklearn.linear_modelimportLinearRegressionlr_clf=LinearRegression()lr_clf.fit(X_train_transformed,y)
1
2
3
4
5
6
# display all scores in one go
defdisplay_scores(scores):print("Scores:",scores)print("Mean:",round(scores.mean()))print("Standard deviation:",scores.std())
# predict for test with linear regression
X_test_matrix=X_test.drop(["price_doc"],axis=1).copy().as_matrix()y_predictions=lr_clf.predict(X_test_matrix)y_predictions=y_predictions.round()linear_results=pd.DataFrame({"id":ids[length:],"price_doc":y_predictions})linear_results.to_csv("data/russian_house_market/linear_results.csv",index=False)
# random forest regressor
fromsklearn.ensembleimportRandomForestRegressorrfr=RandomForestRegressor()rfr.fit(X_train_transformed,y)rfr_predictions=rfr.predict(X_test_matrix)rfr_results=pd.DataFrame({"id":ids[length:],"price_doc":rfr_predictions})rfr_results.to_csv("data/russian_house_market/rfr_results.csv",index=False)
# xgb with test
xgb_predictions=xgb.predict(X_test_matrix)xgb_results=pd.DataFrame({"id":ids[length:],"price_doc":xgb_predictions})xgb_results.to_csv("data/russian_house_market/xgb_results.csv",index=False)