
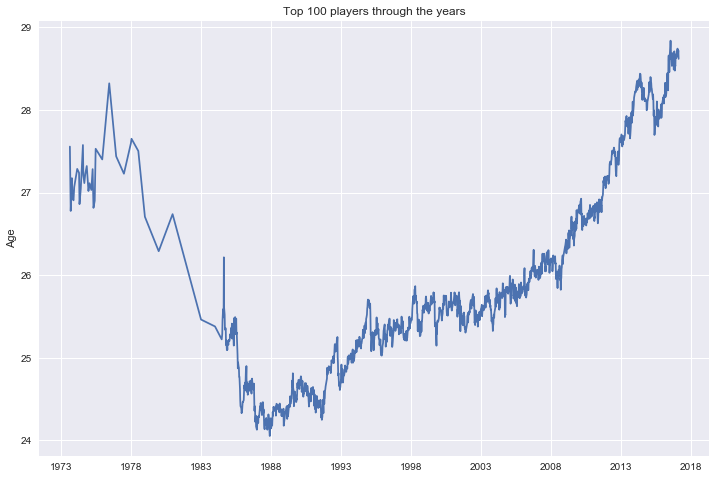
Although the sport is getting more physical we can see that the age of top 100 tennis players has gone up since 1985.
Show the code
1
2
3
4
5
6
7
import pandas as pd
import glob
import matplotlib.pyplot as plt
import datetime, sys
import numpy as np
%matplotlib inline
1
2
3
4
5
6
def parse(t):
string_ = str(t)
try:
return datetime.date(int(string_[:4]), int(string_[4:6]), int(string_[6:]))
except:
return datetime.date(1900,1,1)
1
2
3
4
5
6
7
8
9
10
11
12
13
def readAllFiles():
allFiles = glob.iglob("data/atp_rankings_" + "*.csv")
ranks = pd.DataFrame()
list_ = list()
for filen in allFiles:
df = pd.read_csv(filen,
index_col=None,
header=None,
parse_dates=[0],
date_parser=lambda t:parse(t))
list_.append(df)
ranks = pd.concat(list_)
return ranks
1
2
3
4
5
6
def readPlayers():
return pd.read_csv("data/atp_players.csv",
index_col=None,
header=None,
parse_dates=[4],
date_parser=lambda t:parse(t))
1
2
3
4
5
6
7
8
9
ranks = readAllFiles()
ranks = ranks[(ranks[1]<100)]
ranks = ranks.apply(lambda row: pd.Series({'ranking_date':row[0], 'ranking':row[1], 'player_id':int(row[2]), 'ranking_points':row[3]}), axis=1)
players = readPlayers()
plRanks = ranks.merge(players,right_on=0,left_on="feature3")
plRanks["B"] = plRanks["feature1"] - plRanks[4]
plRanks["B"] = plRanks["B"].astype(int) / (365*24*3600*1000000000.0)
agg = plRanks[["feature1","B"]].groupby("feature1")
data = agg.mean()
1
2
3
4
5
# since 86 the age of top 100 players has gone up
f, ax = plt.subplots(figsize=(12, 8))
ax.plot(data.index.to_pydatetime(), data.B)
ax.set(title='Top 100 players through the years', ylabel='Age')
Full code: https://github.com/ClaudiuCreanga/tennis-statistics