# title from name looks interesting because you can get if the person is married or not and guess their age if it is not known
importre#A function to get the title from a name.
defget_title(name):# Use a regular expression to search for a title. Titles always consist of capital and lowercase letters, and end with a period.
title_search=re.search(' ([A-Za-z]+)\.',name)#If the title exists, extract and return it.
iftitle_search:returntitle_search.group(1)return""X["Title"]=X["Name"].apply(get_title)X_test["Title"]=X_test["Name"].apply(get_title)X["Title"].value_counts()
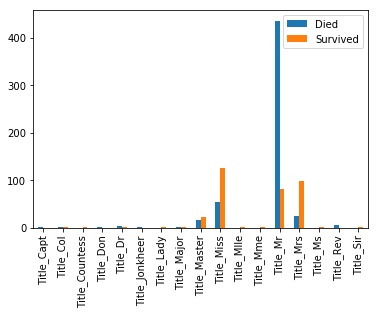
# We can see here that most people with Mr in their title died while Miss and Mrs survived
title_survive=X[["Title","Survived"]]title_survive_transformed=pd.get_dummies(title_survive,columns=["Title"])bar=title_survive_transformed.groupby("Survived").apply(lambdacolumn:column.sum()).transpose().drop(["Survived"])bar.columns=["Died","Survived"]bar.plot.bar()
1
2
3
4
5
6
7
8
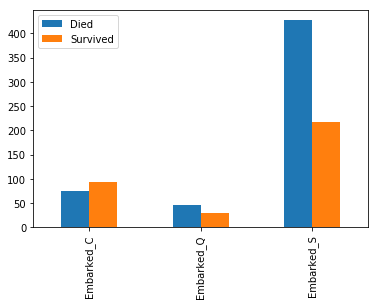
# you can see that you had a greater chance to survive if you were in embarked C or Q
embarked_survive=X[["Survived","Embarked"]]embarked_survive_transformed=pd.get_dummies(embarked_survive,columns=["Embarked"])e_bar=embarked_survive_transformed.groupby("Survived").apply(lambdacolumn:column.sum()).transpose().drop(["Survived"])e_bar.columns=["Died","Survived"]e_bar.plot.bar()
# fill NaN values with mean so that we can do transformations
X.fillna(X.mean(),inplace=True)X_test.fillna(X_test.mean(),inplace=True)X.head()
PassengerId
Survived
Pclass
Name
Sex
Age
SibSp
Parch
Ticket
Fare
Cabin
Embarked
Title
FamilySize
0
1
0
3
Braund, Mr. Owen Harris
male
-0.592481
1
0
A/5 21171
-0.502445
NaN
S
Mr
Large
1
2
1
1
Cumings, Mrs. John Bradley (Florence Briggs Th...
female
0.638789
1
0
PC 17599
0.786845
C85
C
Mrs
Large
2
3
1
3
Heikkinen, Miss. Laina
female
-0.284663
0
0
STON/O2. 3101282
-0.488854
NaN
S
Miss
Single
3
4
1
1
Futrelle, Mrs. Jacques Heath (Lily May Peel)
female
0.407926
1
0
113803
0.420730
C123
S
Mrs
Large
4
5
0
3
Allen, Mr. William Henry
male
0.407926
0
0
373450
-0.486337
NaN
S
Mr
Single
1
2
3
4
5
6
7
8
9
# Age and Fares are on different scales, so let's scale them
fromsklearnimportpreprocessingstd_scale=preprocessing.StandardScaler().fit_transform(X[['Age','Fare']])X[["Age","Fare"]]=std_scalestd_scale_test=preprocessing.StandardScaler().fit_transform(X_test[['Age','Fare']])X_test[["Age","Fare"]]=std_scale_teststd_scale
# transform form categorical to numerical
X_transformed=pd.get_dummies(X,columns=["Sex","FamilySize","Cabin","Title","Embarked"])X_test_transformed=pd.get_dummies(X_test,columns=["Sex","FamilySize","Cabin","Title","Embarked"])
# remove columns that offer little help and the labels
y=X_transformed["Survived"]X_fewer_columns=X_transformed.drop(["Survived","Name","Ticket","PassengerId"],axis=1).copy()X_test_fewer_columns=X_test_transformed.drop(["Name","Ticket","PassengerId"],axis=1).copy()
# display all scores in one go
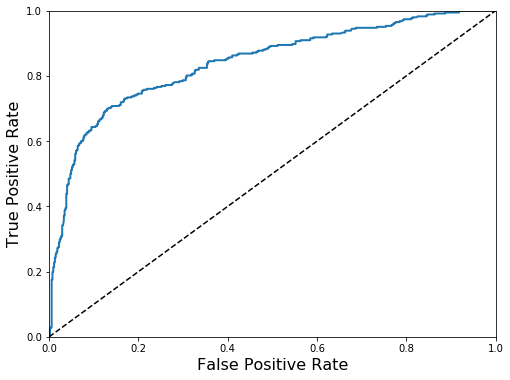
fromsklearn.model_selectionimportcross_val_predictfromsklearn.metricsimportconfusion_matrixfromsklearn.metricsimportprecision_score,recall_scorefromsklearn.metricsimportf1_scorefromsklearn.metricsimportroc_curvedefplot_roc_curve(fpr,tpr,**options):plt.plot(fpr,tpr,linewidth=2,**options)plt.plot([0,1],[0,1],'k--')plt.axis([0,1,0,1])plt.xlabel('False Positive Rate',fontsize=16)plt.ylabel('True Positive Rate',fontsize=16)defdisplay_all_scores(model,X):y_train_predictions=cross_val_predict(model,X,y_matrix,cv=3)print("Scores for model:",model.__class__.__name__)print("Confusion metrics:",confusion_matrix(y_matrix,y_train_predictions))print("Precision score:",precision_score(y_matrix,y_train_predictions))print("Recall score:",recall_score(y_matrix,y_train_predictions))print("F1 score:",f1_score(y_matrix,y_train_predictions))y_scores=cross_val_predict(model,X,y_matrix,cv=3,method="decision_function")fpr,tpr,thresholds=roc_curve(y,y_scores)plt.figure(figsize=(8,6))plot_roc_curve(fpr,tpr)plt.show()
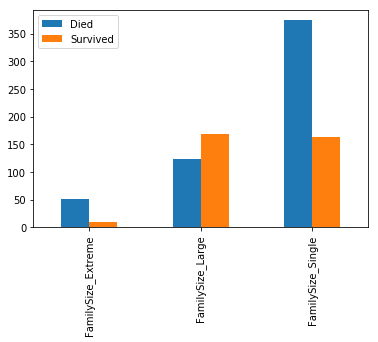
# let's see how we do if we remove more columns that do not look interesting
remove_some_cabins=[cforcinX_fewer_columns.columnsifc[:6]!="Cabin_"andc!="Parch"andc!="SibSp"andc!="Title_Major"andc!="Title_Rev"andc!="Title_Sir"andc!="Title_Jonkheer"andc!="Title_Dr"andc!="Title_Don"andc!="Title_Countess"andc!="Title_Col"andc!="Title_Capt"]X_even_fewer_columns=X_fewer_columns[remove_some_cabins]
# Let's check the Random Forest and you can see that it fares better
fromsklearn.ensembleimportRandomForestClassifierfromsklearn.model_selectionimportcross_val_predictfromsklearn.model_selectionimportcross_val_scoreX_matrix=X_fewer_columns.as_matrix()rf=RandomForestClassifier(n_jobs=2)rf.fit(X_matrix,y_matrix)y_train_predictions=cross_val_predict(rf,X_matrix,y_matrix,cv=3)scores=cross_val_score(rf,X_matrix,y_matrix,scoring='f1',cv=3)print("F1 score for Random Forest",scores.mean())
F1 score for Random Forest 0.727883412153
1
2
3
4
5
6
7
8
9
10
11
12
13
14
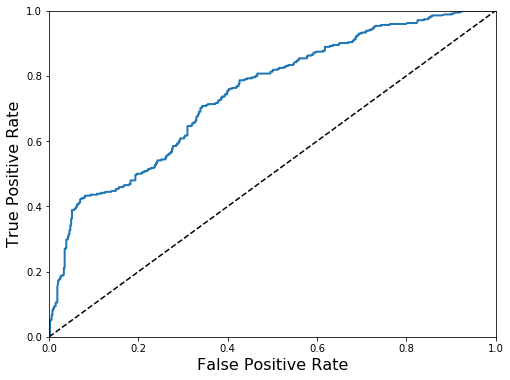
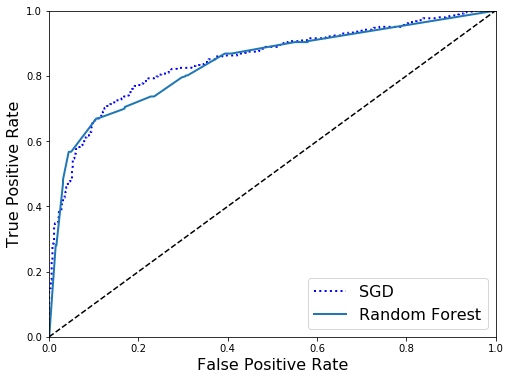
# ROC Curve for SGD vs RFC, showing that they perform about the same
y_probas_forest=cross_val_predict(rf,X_matrix,y_matrix,cv=3,method="predict_proba")y_scores_forest=y_probas_forest[:,1]# score = proba of positive class
fpr_forest,tpr_forest,thresholds_forest=roc_curve(y_matrix,y_scores_forest)y_scores_sgd=cross_val_predict(sgd_clf,X_matrix,y_matrix,cv=3,method="decision_function")fpr,tpr,thresholds=roc_curve(y,y_scores_sgd)plt.figure(figsize=(8,6))plt.plot(fpr,tpr,"b:",linewidth=2,label="SGD")plot_roc_curve(fpr_forest,tpr_forest,label="Random Forest")plt.legend(loc="lower right",fontsize=16)plt.show()
# Let's see how it performs on the test sample
# make the columns equal in number
forcolumninX_fewer_columns.columns:ifcolumnnotinX_test_fewer_columns.columns:X_test_fewer_columns[column]=0forcolumninX_test_fewer_columns.columns:ifcolumnnotinX_fewer_columns.columns:X_test_fewer_columns.drop([column],axis=1,inplace=True)X_test_matrix=X_test_fewer_columns.as_matrix()test_predictions=rf.predict(X_test_matrix)test_predictions_sgd=sgd_clf.predict(X_test_matrix)submission=pd.DataFrame({"PassengerId":X_test["PassengerId"],"Survived":test_predictions})submission_sgd=pd.DataFrame({"PassengerId":X_test["PassengerId"],"Survived":test_predictions_sgd})submission.to_csv("data/titanic_submission.csv",index=False)# both score about 0.72
submission_sgd.to_csv("data/titanic_submission_sgd.csv",index=False)